De onderstaande tekst hoort bij de presentatie
Indeling:
| duur (min) | onderdeel | wie |
|---|---|---|
| 10 | Presentatie: ChatGPT: wat, waarom, hoe? | inleider(s) |
| 20 | Zelf (experimenteel) aan de slag (1) | deelnemers |
| 10 | Presentatie: Beperkingen, ethisch gebruik | inleider(s) |
| 10 | vragen, gesprek hierover | inleider(s) |
| 10 | Presentatie: ChatGPT voor onderwijs | inleider(s) |
| 20 | Zelf (gestructureerd) aan de slag (2) | deelnemers |
| 10 | Afronding, volgende stappen | inleider(s) |
De onderdelen “Zelf aan de slag” bestaan uit een korte instructie, waarna de deelnemers ca. 15 minuten aan de slag gaan. Aan het eind van zo’n onderdeel kun je 5 minuten vragen naar de ervaringen, zowel positieve als negatieve.
ChatGPT: wat, waarom, hoe?¶
ChatGPT is een LLM¶
ChatGPT is een zogenaamd Large Language Model (LLM): een zeer groot speciaal neuraal netwerk dat getraind wordt met een enorme hoeveelheid data. ChatGPT3.5 bevat 175 miljard parameters, onder meer in de vorm van de gewichten in het neurale netwerk. ChatGPT3.5 is getraind op zeer veel data: 300 miljard woorden. Een normaal leesboek bevat zo’n 250-300 woorden per pagina: dat komt dus neer op zo’n miljard pagina’s, ofwel enkele miljoenen boeken. Veel van deze tekst is afkomstig van het web: denk aan Wikipedia, en heel veel andere websites. ChatGPT4 (en later) is ongeveer een orde (factor 10) groter, maar daarvan zijn veel minder gegevens bekend.
Al deze data wordt gebruikt voor met maken van een groot statistisch taalmodel, dat steeds een plausibel volgend woord kiest bij de tekst die tot nu toe ingevoerd en gegenereerd is. Je kunt dit zien als “autocompletion on steroids”
De ChatGPT-aanpak kun je zien als een brute force aanpak: het probleem wordt met zeer veel rekengeweld en zeer veel data aangepakt. Dit blijkt wel goed te werken - maar misschien kan het ook slimmer? De komende jaren zullen we het zien: er wordt ook zeer veel onderzoek naar gedaan.
...en wat is het niet?¶
ChatGPT is een taalmodel, geen kennismodel. Heel veel kennis is op een impliciete manier in de vorm van taal opgeslagen, en die kennis wordt door ChatGPT gebruikt om steeds een plausibel antwoord te geven. Maar ChatGPT kan zelf niet nagaan of het antwoord “waar” is of niet; of wat de feiten zijn waar het antwoord op gebaseerd is, en de redenering.
ChatGPT geeft bovendien niet steeds hetzelde antwoord bij dezelfde invoer: het is geen deterministisch systeem.
ChatGPT is getraind, niet geprogrammeerd. Het neurale netwerk van ChatGPT is wel geprogrammeerd, maar daarna is dit netwerk getraind met zeer veel data. Het resultaat is een statistisch model, niet een regel-gebaseerd model. Dit betekent bijvoorbeeld dat ChatGPT geen uitleg kan geven welke regels gevolgd zijn om tot een bepaald resultaat te komen.
Vergelijking:
- als je leert fietsen, train je je hersenen om op de fiets in evenwicht te blijven, met vallen en opstaan. Je kunt niet uitleggen welke regels je gebruikt om overeind te blijven.
- de verkeersregels leer je op een andere manier, en gebruik je op een andere manier. Je kunt steeds in een situatie uitleggen wie voorrang heeft, en op grond van welke regels dat zo is.
Waarom ChatGPT?¶
...het blijkt verbazend goed te werken...
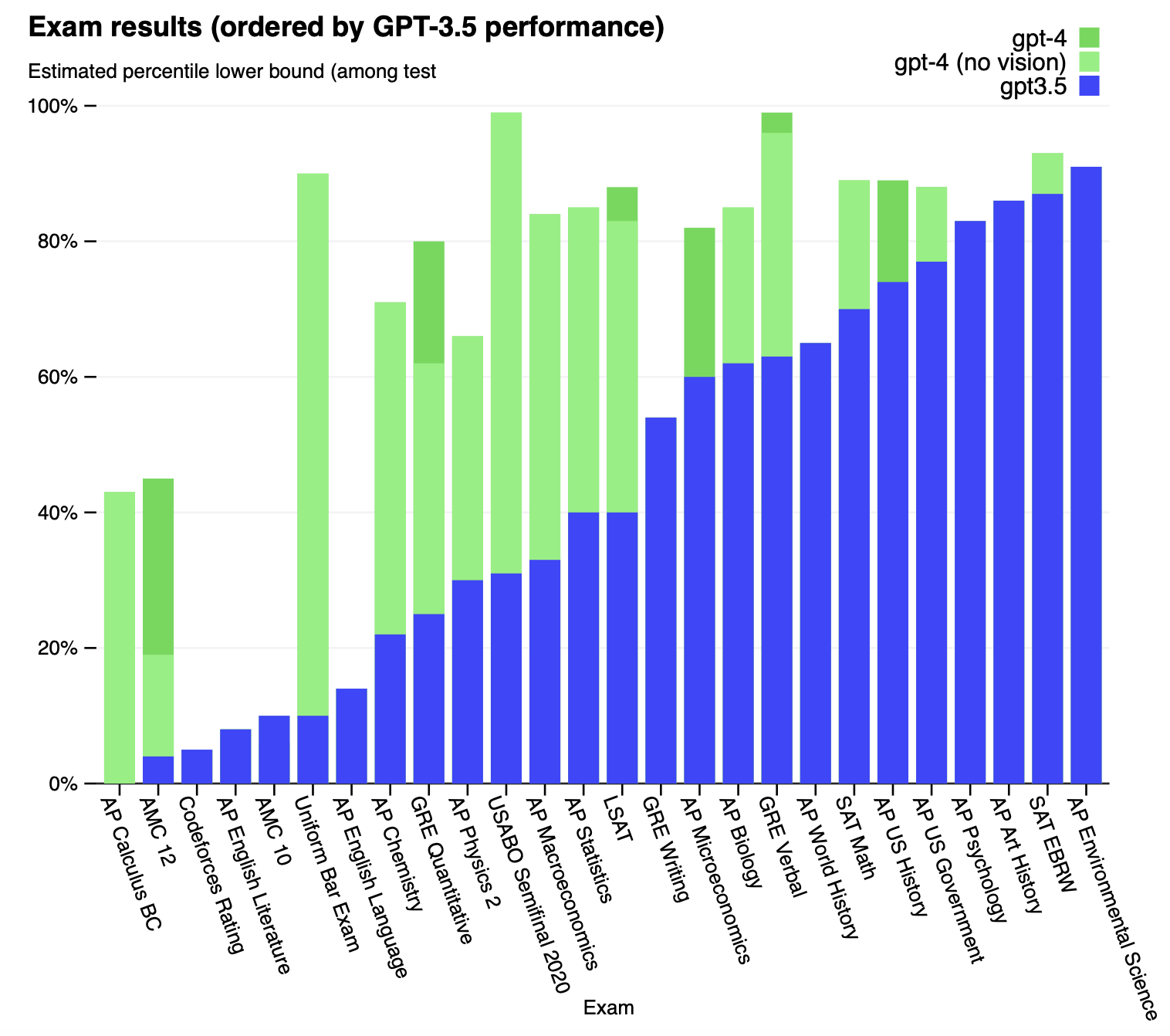
Examenresultaten van ChatGPT
Bill Gates gaf OpenAI de uitdaging om ChatGPT een Biologie-AP examen te laten maken, ongeveer vergelijkbaar met onze eindexamens VWO. Hij koos Biologie omdat het daar niet gaaat om het puur reproduceren van feiten, maar je moet ook kunnen nadenken en redeneren over Biologie. Hij dacht dat die uitdaging ze nog wel twee of drie jaar bezig zou houden. Het werden een paar maanden: zie de groene resultaten van ChatGPT3.5 Dat was voor Gates het teken dat hier van een echte doorbraak sprake was.
Zoals je ziet presteert ChatGPT3.5 al heel behoorlijk voor veel vakken. ChatGPT4 komt nog flink verder (een half jaar later).
Achtergrond
Voor inzichten van Bill Gates over OpenAI en ChatGPT,
zie https://
The second big surprise came just last year. I’d been meeting with the team from OpenAI since 2016 and was impressed by their steady progress. In mid-2022, I was so excited about their work that I gave them a challenge: train an artificial intelligence to pass an Advanced Placement biology exam. Make it capable of answering questions that it hasn’t been specifically trained for. (I picked AP Bio because the test is more than a simple regurgitation of scientific facts—it asks you to think critically about biology.) If you can do that, I said, then you’ll have made a true breakthrough.
I thought the challenge would keep them busy for two or three years. They finished it in just a few months.
(lees ook vooral de rest).
Ondersteuning van professionals¶
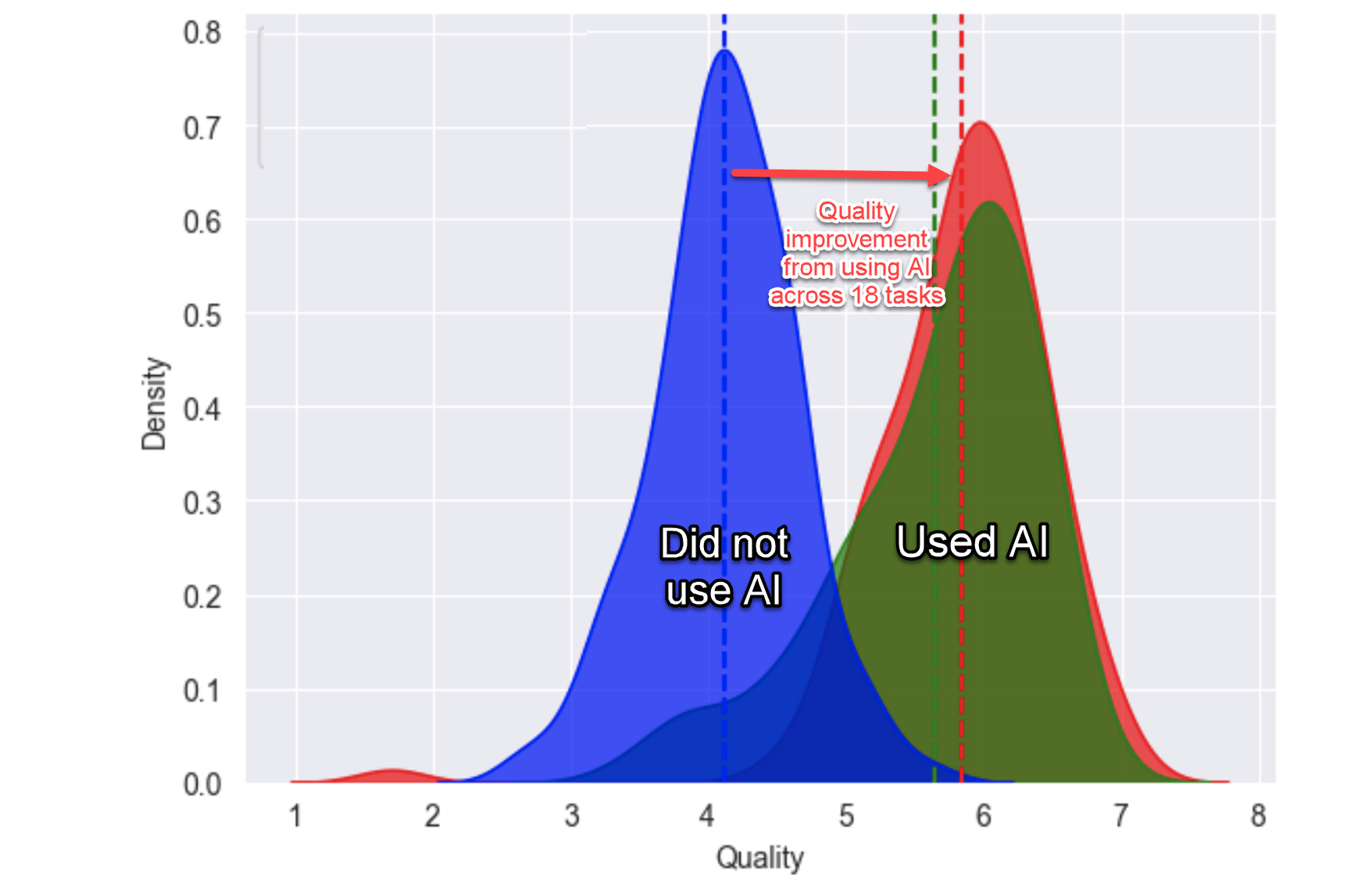
Resultaten van consultants zonder en met gebruik van ChatGPT4
De Boston Consultancy Group heeft een wetenschappelijk experiment gedaan: een groep consultants werd in tweeën gesplitst, waarbij de ene groep wel gebruik maakte van ChatGPT4, en de andere groep niet. Daarna moesten ze 18 taken uitvoeren die representatief zijn voor hun dagelijkse consultancy-werk.
Het resultaat zie je in de grafiek:
- de groep die ChatGPT4 gebruikte had maar 75% van de tijd nodig vergeleken met de andere groep;
- de resultaten van deze AI-ondersteunde groep waren ca. 40% beter dan die van de andere groep.
De resultaten van de AI-ondersteunde consultants waren allemaal beter dan hun normale niveau, maar dat gold het sterkst voor de gewoonlijk minder presterende professionals: deze gingen er zeer sterk op vooruit.
Een dergelijke verbetering geen professional en geen bedrijf laten liggen.
Achtergrond
Het experiment met de consultants van de Boston Consultancy Group wordt besproken in de blog oneusefulthing: Centaurs and Cyborgs on the jagged frontier
There is a ton of important and useful nuance in the paper but let me tell you the headline first: for 18 different tasks selected to be realistic samples of the kinds of work done at an elite consulting company, consultants using ChatGPT-4 outperformed those who did not, by a lot. On every dimension. Every way we measured performance.
Nog enkele opvallende punten:
- zowel menselijke experts als ChatGPT gaven een beoordeling van de resultaten. Beide waren het vrijwel altijd eens;
- de AI-ondersteunde groep is niet speciaal getraind voor het gebruik van ChatGPT.
Het working paper zelf vind je hier.
...soms gaat het mis...¶

De grillige grens tussen succes en falen van ChatGPT
Het resultaat van ChatGPT is vaak goed, maar soms gaat het subtiel of spectaculair mis. ChatGPT verzint dan een plausibel antwoord dat feitelijk onjuist is.
ChatGPT kan een referentie naar een artikel geven van een bestaande auteur. De referentie voldoet aan alle eisen van een wetenschappelijke referentie, en ziet er plausibel uit - maar de betreffende auteur heeft het artikel niet geschreven. Op grond van haar expertise had ze dat artikel kunnen schrijven - maar dat is nooit gebeurd.
Een jurist in de USA is hiermee bij de rechtbank onderuit gegaan: de jurisprudentie die hij aanhaalde (via ChatGPT verzameld) was bedacht.
In zo’n geval spreken we wel over het “hallucineren van generatieve AI”.
Er is een grillige grens tussen wat wel en wat niet goed gaat. Soms gaat een geval waarvan je denkt dat het relatief eenvoudig is, faliekant mis. En soms gaat een moeilijk geval verrassend goed.
Conclusie: je moet altijd het resultaat van ChatGPT controleren. Hiervoor heb je goede informatievaardigheden nodig, geholpen door relevante kennis.
Achtergrond
Voor de “grillige grens” (jagged frontier), zie: Centaurs and Cyborgs on the jagged frontier
Hoe gebruik je ChatGPT?¶
ChatGPT heeft geen handleiding.
Voor een deel is deze misschien niet nodig, omdat het interface heel eenvoudig is: je geeft opdrachten in natuurlijke taal, en krijgt antwoord in natuurlijke taal. (Of, in de vorm van een plaatje, als je daarom vraagt.)
Maar: de makers van ChatGPT weten zelf ook eigenlijk niet hoe het werkt, en aan welke “knoppen” je kunt draaien om een goed resultaat te krijgen. Bovendien weten ze helemaal niet hoe ze ChatGPT het best kunnen aanpassen aan jouw specifieke situatie.
De beste manier is daarom om zelf aan de slag te gaan met ChatGPT, en te experimenteren met verschillende mogelijkheden. Na een aantal uren experimenteren krijg je een gevoel voor wat werkt en wat niet. (Je traint op deze manier jezelf in het gebruik van ChatpGPT.) Je kunt dit het beste doen met je dagelijkse taken, vooral als die wat lastiger zijn of veel tijd kosten.
Als je een eerste reactie krijgt die je niet bevalt, vraag ChatpGPT dan om een aanvulling of een verbetering: vraag door en stuur bij totdat je een bevredigend resultaat krijgt. Je voert een gesprek met ChatpGPT totdat het resultaat goed is (conversational prompting).
(Later in deze workshop ga je aan de slag met gestructureerde prompts, maar probeer eerst zelf uit wat voor jou werkt en wat niet.)
Achtergrond
In zijn blog two paths to prompting maakt Ethan Mollick onderscheid tussen conversational prompting, zoals hier bedoeld, en structured prompting.
Zelf aan de slag (1)¶
Bij dit onderdeel ga je zelf experimenteren met ChatGPT. Stel vragen die je kunnen helpen bij je dagelijkse praktijk, voor school of voor thuis. Of ga op de creatieve toer, bijvoorbeeld met gedichten of met fantasie-verhalen. Als het eerste antwoord je niet helemaal bevalt, vraag dan om het aan te passen: je voert een gesprek om tot het gewenste resultaat te komen.
Dit soort experimenten is belangrijk om een gevoel te krijgen voor de manier waarop ChatGPT werkt: wat werkt wel, wat werkt niet.
Houd er rekening mee dat ChatGPT soms “hallucineert”, en misschien wel een plausibel, maar niet een “waar” antwoord geeft. En denk eraan dat ChatGPT niet deterministisch is: eenzelfde vraag kan verschillende antwoorden geven. (Je kunt om een ander antwoord vragen door de “regenerate” knop.)
ChatGTP in het onderwijs¶
Kansen, beperkingen en ethisch gebruik
Drie belangrijke punten bij het gebruik van ChatGPT in het onderwijs (volgens Mollick & Mollick):
- ChatGPT is overal (en laagdrempelig) beschikbaar
- ChatGTPT is transformatief - disruptive innovation
- het gebruik van ChatGPT is niet detecteerbaar
Overal beschikbaar. Er zijn allerlei manieren om toegang te krijgen tot
ChatGPT en andere LLMs, van gratis versies tot betaalde versies.
De gratis versies lopen wat achter in de technologie, maar zijn voor veel doeleinden
ook goed te gebruiken. Zowel OpenAI als Microsoft (Bing) en Google (Bard)
bieden gratis versies aan.
Ook de betaalde versies, van bijvoorbeeld OpenAI (ChatGPT 4 Plus) maar ook van
Khan Academy (Khanmigo) zijn voor veel mensen te betalen.
(Die kosten zijn veel lager dan bijlessen of examentraining.)
ChatGPT is transformatief. ChatGPT heeft alle kenmerken van een disruptive innovation: deze zet de bestaande verhoudingen op de kop. Dit betekent dat je over veel zaken, bijvoorbeeld in het onderwijs, op een fundamentele manier moet nadenken wat de betekenis ervan is in een wereld met AI. (Dit denken is in veel domeinen, bijvoorbeeld in het onderwijs, nog maar net begonnen.)
ChatGPT is niet detecteerbaar. Je kunt niet detecteren dat het resultaat gemaakt is met behulp van AI. Ook al vallen veel leerlingen nu nog door de mand, bijvoorbeeld door een taalgebruik dat niet bij hen past, dat zal in de nabije toekomst al “gerepareerd” zijn. (Een voorbeeld is een leerling die aan ChatGPT aangaf dat het resultaat eruit moest zien als gemaakt door een dyslectische leerling. Het resultaat bevatte precies de fouten die je van zo’n leerling verwacht.)
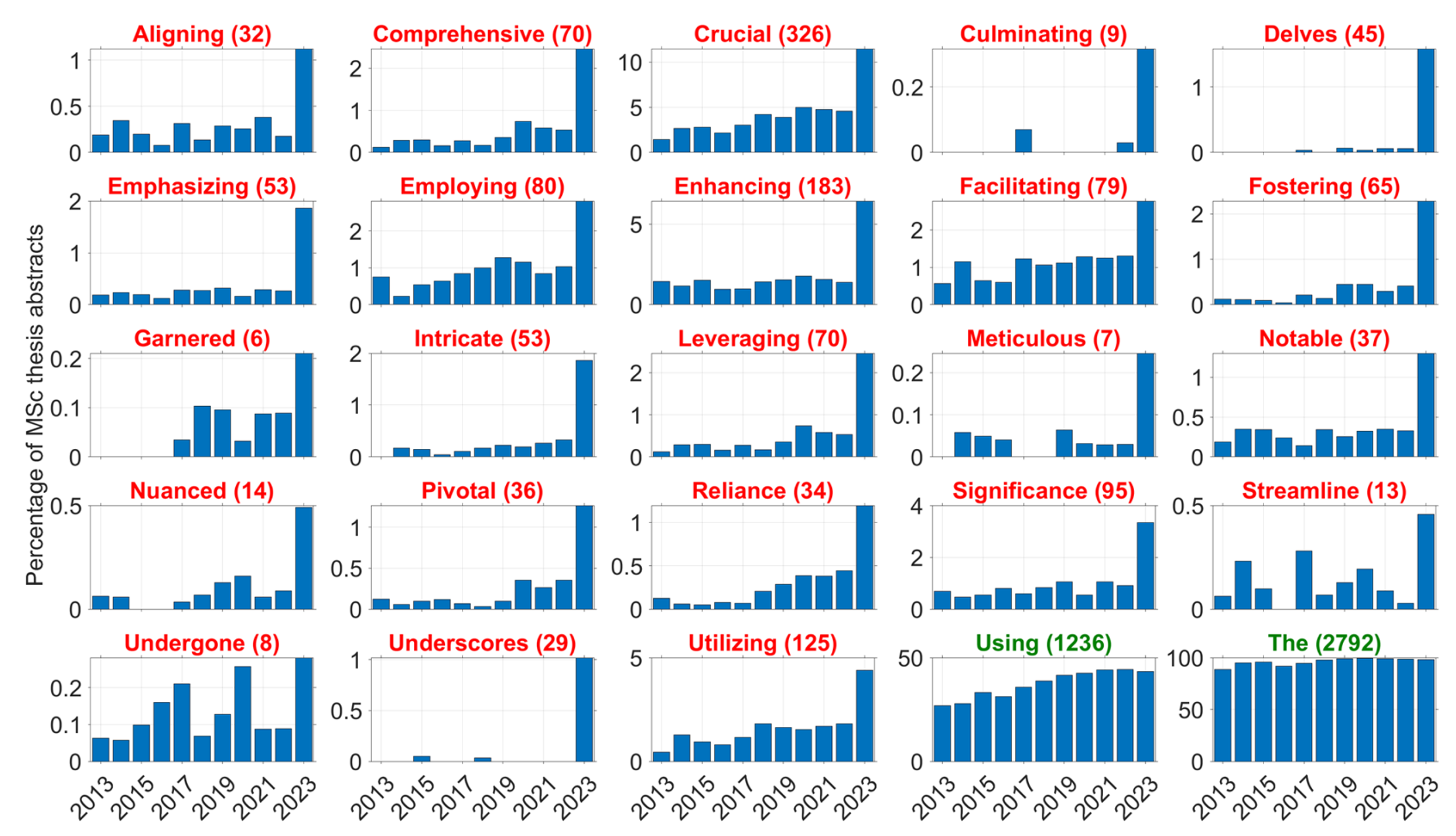
Prevalence of target words (red) and control words (green) in the meta-data of
MSc theses in the TU Delft education repository.
The number in parentheses represents the total number of abstracts in the year 2023
(source: https://
De figuur hierboven geeft het resultaat van een taal-analyse van afstudeerscripties van studenten uit Delft. Na de introductie van ChatGPT in november 2022 komen ineens veel meer minder gangbare Engelse woorden in deze scripties voor. Dit doet vermoeden dan deze studenten AI gebruikt hebben voor het schrijven van hun scriptie. (Voor zover bekend is heeft deze lichting niet een extra cursus Engels gekregen.) Een student die zijn taalgebruik wil aanpassen kan ChatGPT gewoon een aantal voorbeeld-documenten geven, bijvoorbeeld oudere afstudeeerscripties, om dit effect te vermijden. (Bron: Can ChatGPT be used to assess students work? (preprint))
Ondersteuning van professionals - ook voor docenten?¶
We hebben eerder gezien dat ChatGPT consultants helpt om hun werk (veel) beter te doen, in minder tijd. (Ook bij programmeurs zien we soortgelijke verbeteringen.)
Kan ChatGPT ook docenten op een dergelijke manier helpen? Hier kom je alleen achter door dit zelf te proberen, door ervaringen met elkaar te delen, en door van elkaar te leren.
(Een mogelijke vorm is om als PLG of DOT met een groepje collega’s elkaa regelmatig hierover te spreken, bijvoorbeeld elke 4 weken 1,5 uur, gedurende een jaar of langer.)
Bloom’s 2-sigma probleem¶
Benjamin Bloom, bekend van o.a. Bloom’s taxonomy, heeft veel onderzoek gedaan Hij heeft onderzoek gedaan naar manieren hoe je het onderwijs (dus aan de kant van de docent) kunt verbeteren voor betere leeruitkomsten.
Eén van de manieren daarvoor is mastery learning. Daarbij mag een leerling pas verder met het volgende onderwerp, als deze het huidige goed beheerst (op het niveau van een 8 of een 9). De leerling krijgt extra oefening en extra tijd om dat niveau te bereiken.
(Mastery Learning is vooral van belang bij vakken waar kennis en vaardigheden “stapelen”, zoals bij de Bèta-wetenschappen. Bij Geschiedenis is dat misschien minder van belang.)
Het blijkt dat mastery learning in klasverband een verbetering geeft ten opzichte van de “normale” manier van werken van 1 sigma (1 standaarddeviatie). Dat komt ongeveer overeen met 1,5 tot 2 punten (in ons cijfermodel).
Je kunt een nog veel grotere verbetering krijgen, van 2 sigma, door leerlingen 1 op 1 met een goede tutor te laten werken, die op elk moment de leerling precies de juiste uitdaging geeft (als in een computer game).
Kunnen we met een AI-gebaseerde tutor mogelijk een dergelijk effect benaderen? Dat zou een revolutie in het onderwijs betekenen!
Achtergrond
Zie Wikipedia: https://
Het oorspronkelijke artikel van Bloom uit 1984: https://
Bloom, Benjamin S (June–July 1984). “The 2 Sigma Problem: The Search for Methods of Group Instruction as Effective as One-to-One Tutoring” (PDF). Educational Researcher. 13 (6): 4–16. doi:10.3102/0013189x013006004. S2CID 1714225.
Uitdaging volgens Bloom: find methods of group instruction as effective as one-to-one tutoring.
Over mastery learning:
- students must achieve a level of mastery (e.g., 90% on a knowledge test) in prerequisite knowledge before moving forward to learn subsequent information on a topic.
Failure for a student to achieve mastery is viewed, differently from conventional educational testing, as due to instruction rather than lack of student ability.
Op elk moment de juiste uitdaging: zie de “Zone of Proximal Development” (ZPD) van Vygotski (Zone of proximal development). In het Nederlands: de zone van naaste ontwikkeling.
Khanmigo¶
De Khan Academy probeert een dergelijke AI tutor te maken, Khanmigo, op basis van CHatGPT. Deze is op de volgende manieren gespecialiseerd:
- voor leerlingen gedraagt deze zich als zeer geduldige tutor:
- helpt leerlingen bij het maken van hun opdrachten
- maar, zegt geen antwoorden voor, en maakt hun huiswerk niet
- transparant naar docent (en ouders): deze kunnen zien wat een leerling gedaan heeft, zoals de chat-geschiedenis met de tutor.
- voor docenten is dit een goede assistent:
- houdt de voortgang van de leerlingen bij
- helpt met het voorbereiden van lessen e.d.
- de meeste AI risico’s worden vermeden:
- geen inbreuk op privacy e.d.
- blijft veilig binnen de “grillige grens”, minimaal risico op hallicunaties
- blijft bij het onderwerp
Op dit moment (nov. 2023; feb. 2024) is Khanmigo alleen nog maar beschikbaar in de USA.
Zie: https://
Achtergrond
Zie bijvoorbeeld de video: https://
Gebruik ChatGPT als tutor¶
Je kunt ChatGPT ook “programmeren” als tutor in een bepaald onderwerp.
Dit kan door middel van een conversatie-prompt: als leerling (gebruiker) kun je steeds doorvragen op die punten waar je verheldering, uitleg, voorbeelden, oefeningen, e.d. wilt. Dit vraagt wat meer initiatief en oefening.
Het kan ook door middel van gestructureerde prompts". Voorbeelden daarvan vind je in de bijlage en in het boek Chatten met Napoleon.
Sinds kort kun je via een uitgebreide gestructureerde prompt, eventueel aangevuld met eigen documenten, een gespecialiseerde tutor-GPT maken. Het ligt in de verwachting dat hiervan meerdere voorbeelden beschikbaar komen via de “ChatGPT markt”.
Punt van zorg: betrouwbaarheid¶
ChatGPT is een taalmodel, geen kennismodel: heeft geen “begrip van waarheid”. ChatGPT geeft op grond van de trainingsdata een plausibel antwoord - dat niet waar hoeft te zijn. Hoe ga je daar mee om?
Je moet het antwoord altijd controleren* - en dat vraagt beslist om goede informatievaardigheden.
Een andere zorg is dat je veel uitingen op het web zult krijgen die met generatieve AI zoals ChatGPT gemaakt zijn. Deze zijn niet “van echt te onderscheiden” - bijvoorbeeld toespraken van bekende personen, foto’s of video’s van bekende personen - die wat inhoud betreft (net iets) anders zijn dan je verwacht.
Hoe weet je dan of het om echte foto’s en video’s gaat? Om dat goed uit te zoeken, moet je echt goede informatievaardigheden hebben.
Achtergrond
Een groep met zeer goede informatievaardigheden is Bellingcat (https://
Zie bijvoorbeeld: hoe onderscheid je feit en fictie op sociale media in tijden van oorlog
Punt van zorg: bias¶
Als je een LLM vraagt om een arts of van een advocaat te tekenen, dan zul je in veel (te veel) gevallen een tekening krijgen van een blanke man in die rol. Dat komt doordat de data waarmee de meeste LLMs getraind zijn, sterk gekleurd is; ofwel, een bias bevat.
Veel data heeft een dergelijke bias: denk aan de medische onderzoeken, die vaak gedaan worden met mannen van 25-35 jaar; of sollicitatiegegevens, die de verborgen voorkeuren van de sollicitatiecommissies weergeven.
Als je hier alert op bent, kun je bij je opdrachten ook aangeven hoe je wilt dat het resultaat eruit moet zien, bijvoorbeeld een tekening van een jonge afrikaanse vrouw als arts.
Punt van zorg: privacy¶
Anders omgaan met huiswerk¶
Je kunt niet nagaan of leerlingen voor het maken van hun huiswerk gebruik gemaakt hebben van ChatGPT - net zomin overigens als je weet of hun ouders of oudere broer of zus geholpen hebben.
Dit betekent dat je op een andere manier moet omgaan met het maken van huiswerk.
Je kunt leerlingen toestaan om ChatGPT te gebruiken bij hun huiswerk, maar dat ze zich wel aan een aantal regels moeten houden:
- ze moeten de gebruikte prompts en de antwoorden erbij vermelden;
- ze moeten de gebruikte antwoorden gecontroleerd hebben;
- ze moeten wat ze inleveren kunnen uitleggen: als je er vragen over stelt, moeten ze die kunnen beantwoorden.
Je kunt soms ook (veel) hogere eisen stellen aan de opdracht; bijvoorbeeld, een werkende website in plaats van een powerpoint-prototype.
Je moet leerlingen goed duidelijk maken wat de rol van huiswerk is, en daarbij passende opdrachten geven.
Leer studenten LLMs te gebruiken als hulp bij het leren en bij het uitvoeren van taken, niet voor het maken van opdrachten waar je van zou kunnen leren.
De zekerste manier om ervoor te zorgen dat computers later je werk overnemen, is om ze nu je huiswerk te laten maken.
Je traint dan wel de computers, maar niet jezelf.
Gestructureerde prompts¶
Eerder ben je aan de slag gegaan met “conversational prompts”. Een andere, complementaire, aanpak is het gebruik van gestructureerde prompts. Door het gebruik van bepaalde elementen kun je ChatGPT sturen in een bepaalde richting.
Bijvoorbeeld:
- geef ChatGPT een bepaalde rol of persona
- beschrijf de taak die ChatGPT moet uitvoeren duidelijk en precies, eventueel in de vorm van een stappenplan of een aantal voorbeelden.
- beschrijf de context van de taak
- beschrijf de doelgroep
- beschrijf de vorm van het resultaat dat je verwacht.
Het boek Chatten met Napoleon bevat veel voorbeelden van dergelijke gestructureerde prompts, voor allerlei situaties in het onderwijs, voor docenten en voor leerlingen.
In het begeleidende materiaal bij deze cursus zijn varianten te vinden van de prompts van Mollick & Mollick.
Achtergrond
Een uitleg met voorbeelden van prompting voor onderwijs: voor docenten en voor leerlingen.
- video in de reeks AI 101 for Teachers, https://
code .org /ai /pl /101, met document met prompt-voorbeelden voor docenten - aflevering “Demystifying AI for Teachers”
- https://
docs .google .com /presentation /d /1WXvjG9TscUuH5Xz8Pj2okz6lMIKV _ _g0v6AoYVXKb40 /copy
- idem, voor studenten (leerlingen)
- aflevering “Transforming Learning with AI” (Mollick & Mollick)
- https://
docs .google .com /document /d /1E74yMRBBy6UDTueKm2rNHHNkKSTh0LjjADArun7Lz9w /edit
- https://
github .com /microsoft /prompts -for -edu /tree /main - Microsoft’s verzameling van de prompts van Mollick & Mollick voor onderwijs.
Enkele blog-posts van Ethan Mollick over prompting:
Sommigen maken een echte studie van “prompt engineering”. Maar het is de vraag hoeveel dat op termijn oplevert, omdat de manier waarop ChatGPT en andere LLMs hiermee omgaan voortdurend evolueert.
Zelf aan de slag (2)¶
In plaats van een “vrije prompt” kun je ook gebruik maken van een gestructureerde prompt. Deze bevat een aantal elementen waarmee je de interactie tussen ChatGPT en de gebruiker stuurt. Typische elememten zijn: de persona (rol) voor ChatGPT, de taak in detail beschreven, de context (extra invoer e.d.), de regels waaraan de uitvoer moet voldoen.
In het boek staan veel gestructureerde prompts beschreven, voor allerlei soorten taken, vooral gericht op onderwijs. In de bijlage Gestructureerde prompts vind je een aantal voorbeelden van Mollick & Mollick, gericht op onderwijs, voor zowel docent als leerling (student).